Technology Blog
New generation parallel storage technology
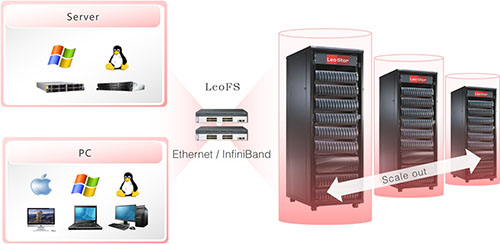
Architecture
LeoStor believes that the application is the application of files, not the application of block devices. Block devices are only the intermediate state of file applications, and are the technical products of traditional stand-alone applications. Therefore, LeoStor first built a layer of high-performance LeoFS global parallel file system, and then built a storage application protocol on it. LeoStor supports block devices through "Virtual Block File" (VBF) technology, that is, vSAN technology. VBF is a group of files saved on LeoFS. Each block device is divided into a group of files by directory. In the comparative test, the performance of the 2U12 SATA mechanical disk configuration is better than that of the mid-range storage array devices of foreign professional storage manufacturers.


"Slice" or "copy" the data and save it on different hard disks of different storage nodes, which is the concept of "distributed". These data are called "object data"; Some distributed "LAN" based designs, such as LeoStor and Ceph, and some WAN based designs, such as IPFS. LAN products pursue absolute performance and reliability, and WAN products pursue data availability.


No matter what kind of distributed technology, there must be metadata storage or indexing algorithm for metadata, otherwise the object data cannot be found. Generally, there are two technologies, one is metadata (object index value)+hash index algorithm, the other is metadata (HASH configuration scheme)+hash index. The first is mostly used on global file systems, such as LeoStor and IPFS, and the second is mostly used on block device systems, such as Ceph.


The LeoFS host client obtains file data in the following steps:
- Obtain the file slice location information from the MDS metadata node, including the IP address and hard disk ID number of the OSS storage node;
- According to the location information, request data directly and concurrently to all relevant OSS storage nodes;
- Assemble data on the host client and provide it to the upper application through the file POSIX interface of the operating system;
LeoFS quickly locates the metadata location of the MDS node of the file through the hash algorithm, and quickly locates the OSS node through the node and hard disk information of the file slice. The system uses the connection pool technology to ensure that each request responds quickly.
Read and write mechanism
LeoFS is a global file system that conforms to the POSIX file standard. Its output shared directory is used by applications. The client application does not need secondary development, and can directly mount the directory for use; The system does not limit the number of clients accessing the shared directory. It has an efficient file lock that conforms to the POSIX standard and supports multiple reads and writes of the same file.
LeoStor has intelligent small file aggregation technology, which can aggregate small KB files into large MB files. The size of LeoFS slice is 64K~512MB. The system adjusts the data intelligently, and the slice data conforms to the LeoRaid rule. When the file is not less than N * 64MB, the integer multiple of N * 64MB is cut into N pieces according to 64MB, and the check bit is generated for storage, while the remainder is cut into N pieces, and the check bit is generated for storage; When the file is smaller than N * 64MB, the file is cut into N slices and regenerated into check bits for storage; The same is true for the replica mode. If it is less than 64MB, it is directly stored. If it is more than 64MB, the integer multiple of 64MB is sliced as 64MB, and the remainder is stored as a slice.
| 200MB file LeoRaid 2+1 | |||
| 0~64MB | OSS-1 | Erasure code | OSS-5 |
| 65MB~128MB | OSS-2 | ||
| 129MB~164MB | OSS-3 | Erasure code | OSS-6 |
| 165MB~200MB | OSS-4 | ||
The directory data is saved in the metadata node, and the file data is saved in the storage node; When creating a new file, the client uses the load balancing algorithm to locate a group of metadata nodes with lighter tasks and less data volume; When writing data, the client sends a Block application to the metadata, returns the relevant storage node value according to the metadata, and sends the data directly to the storage node; When reading data, the client sends a location request to all metadata nodes. The system has one and only one to return the location data. After the client obtains the location data, it requests data from the relevant storage nodes.
Storage Services
Through the layered mode of "elastic storage" and "application protocol", LeoStor has stronger vitality and wider application scenarios. LeoFS solves high-performance and highly reliable elastic storage management, and storage application protocols solve application scenarios. Through the integrated deployment architecture of storage nodes, high-performance unified storage systems including "file storage", "object storage" and "block storage" can be easily built. In future use, users can also freely add storage protocols to improve the life cycle of storage. At the same time, LeoStor LTM/GTM load balancing module is used, It can construct high concurrency and high reliability storage services.


Linux and Mac OS can mount LeoFS through the mount command, and Windows can mount LeoFS through the drive or directory. The path to be mounted can be specified arbitrarily, but the security management specification of business data should be followed to avoid some applications seeing too many directories or data. Mount paths are managed in accordance with multi-level directories such as "cluster name">>"tiered storage">>"storage type">>"application data". Standardized data management is the guarantee of data disaster recovery and data replication!
Data access security
"Storage out of bounds" and "illegal access" are the most critical issues of storage system access. LeoFS manages data overrun through directory hard quota. When the data stored in the directory exceeds the quota, even if there is one more byte, the application will return a standard POSIX write file error; LeoFS can set the file permissions to read, write, delete, query, link, rename, append and write the directory data for each host client that mounts the directory to prevent illegal access; At the same time, you can set the "WORM" permission of the directory to ensure that the super-administrator has no excessive read, write and delete permissions, and ensure data access security.
The actual deployment case of using host permission management: a portal site prevents the configuration of web page content from being tampered with. One content management server, four web application servers, located in different network segments, are deployed using virtual machines. Five devices can see the same web directory. In the LeoStor management interface, the content management server host is configured as "all permissions", and the other four web hosts are configured as "read-only" permissions. In this way, Even if hackers attack the Web server, they cannot modify the content of the Web page.
SSD acceleration
Competitive products mostly use SSD acceleration to improve the read and write bandwidth of the system. LeoStor has excellent parallel architecture and data scheduling algorithm. Without SSD hard disk acceleration, it can surpass the competitive products with cache. The 4U36 disk SATA mechanical disk device can output 2GB/s shared file bandwidth per node, and the system performance can increase linearly with each addition of a node or a hard disk. In the pre-sale test and actual use of many cases, LeoStor is significantly superior to Ceph series products; LeoStor can predict the actual output bandwidth of the system by the number of hard disks deployed at the project initiation stage, and can also reverse the number of hard disks required by how much bandwidth is required to make the investment more accurate
The Linux bcache scheme is often used for SSD cache acceleration. The cache disks are SATA SSDs and U.2 NVME SSDs. Bcache supports three cache modes: Writeback (write first and then save), Writethrough (write at the same time) and Writearound (write save read slow); For writeback, if it is a dense write and cannot be written back to the storage disk due to SSD disk failure, the probability of data loss will increase, which is the application risk; For Writethrough, from the perspective of bucket theory, there is no deployment significance; For Writearound, reading can speed up, but writing is still slow.
Therefore, LeoStor's "direct drop" storage mechanism plays the most powerful role in ensuring "data security" in actual cases.